[44호]참! 잘했어요!

2017 ICT 융합 프로젝트 공모전 입선작
참! 잘했어요!
글 | 건국대학교 신한순, 고형규
심사평
칩센 빅데이터 활용을 위한 스마트폰용 어플리케이션이 주된 내용으로 보이고, 그것을 구현하기 위한 제품에 대한 고민은 크게 많지 않았던 듯 합니다. 음성 인식 및 수집을 위한 장치로 블루투스를 고려하였는데, 만약 블루투스 팔찌가 스마트폰과 연결되어 있는 상태라 치더라도, 사용자가 말하는 자연어가 그대로 전송될 수 있을 만큼 무선 성능이 뒷받침 되는지의 여부와, 대화에서 사용자의 어휘인지 아니면 상대의 어휘인지를 구분해야하는 방법에 대한 고민이 필요할 듯 하고, 휴대용 무선기기의 가장 큰 이슈는 배터리 이슈인데, 이 부분에 대한 고려도 필요합니다. 화자의 단어를 명확하게 인식, 전송 및 sorting이 가능하다면 활용도 면에서는 다양한 방법으로 사용이 가능할 듯 한 가능성은 보입니다.
뉴티씨 제가 생각하기에 아주 괜찮은 작품 같습니다. 전체적인 완성도와 작품성이 좋습니다. 다만, 이 기능을 어플리케이션으로만 구현해도 되지 않았을까 싶은 작품입니다.
위드로봇 일상의 음성을 녹음하여 통계적으로 분석한 수치를 제공하는 아이디어가 참신합니다. 음성 인식률이 관건인데, 이 부분에 대한 추가 연구가 필요할 것으로 보입니다.
작품개요
작품 개발동기
본 아이템은 일기장이나, 녹음기와 같이 ‘그 날 있었던 일을 쉽게 돌아보면 좋지 않을까’라는 생각으로 생각하게 되었다. 사람은 24시간 필기하며 다니지 않는 이상 당일 무슨 일이 있었는지, 대화나 회의의 내용은 어떠했는지, 어떤 실수를 했는지, 말버릇이나 습관이 어떤 지를 본인 스스로 잘 알 수 없다.
위와 같은 기억하지 못하는 상황을 해결함과 동시에 이를 분석해 여러 그래픽 통계자료로 보여준다면 유의미한 결과가 있을 것이라 생각했다. 사용자가 오늘에 있어 가장 관심이 있었던 키워드는 무엇인지, 의도적으로 피하려고 했던 키워드는 무엇인지를 녹음과 분석을 통해 알 수 있다는 것은 보다 쉽고 간편하게 사용자의 하루를 피드백 해주는 것이라 생각했다. 따라서 이러한 사용자에게 일상을 피드백 해 생활에 도움이 될 수 있도록 하는 팔찌와 어플리케이션 시스템을 만들어보고자 한다.
추진 배경
본 팀은 건국대학교 글로컬캠퍼스에 소재하고 있는 컴퓨터공학과 창업동아리 IctShare 팀의 구성원으로 이루어져 있어, 창업 아이디어 창출과 아이템 개발 경험이 많고 관련 기술을 다수 보유하고 있다. 이러한 배경 속에서 아두이노를 이용할 수 있는 숙련자들이 있음과 동시에 빅데이터를 이용한 아이디어로써 창업 아이템을 만들 수 있을 것이라 생각했다.
아두이노와 블루투스 모듈 등 시제품 제작에 필요한 물품 지원은 건국대학교 글로컬캠퍼스 컴퓨터공학과 학과사무실을 통해 지원받을 수 있도록 하고, 어플리케이션은 자체 제작할 수 있도록 한다. 1차 시제품 제작을 통해 아이디어의 효과 검증과 실현 가능성을 실험해보았고, 다음으로 사업성을 검증하기 위해 여러 실험과 설문조사를 진행하고 있다.
아이템 개요
“참 잘했어요”는 일상을 요약하고 분석통계를 통해 하루를 피드백받는 팔찌와 어플리케이션 시스템이다. 팔찌를 통해 일상에서 있는 대화를 녹음하고 이 음성데이터를 스마트폰으로 송신한다. 데이터를 분석통계하여 사용자에게 보여주어 본인 피드백을 돕는 어플리케이션이다. 이를 통해 사용자는 쉽게 본인의 습관, 관심사 등을 파악할 수 있을 것이라 예상하고, 더 나아가 생활 전반의 개선을 가져다 줄 것으로 예상된다.
기대효과
이러한 효과를 이용한다면 스스로에게 어떠한 말버릇이 있는지, 실수는 하지 않았는지, 자신이 당장 필요한 것이 무엇인지 등을 확인하여 사용자들의 니즈를 충족시켜 줄 뿐만 아니라 더욱 스마트한 삶을 살 수 있을 것으로 예상된다.
본인의 하루를 피드백할 수 있게 된다. 오늘 자신이 말한 말들을 알 수 있고, 그것을 쉽고 간편한 통계로서 접하게 된다면 일기를 쓰는 것과 같은 효과를 얻을 수 있다고 생각된다. 이를 통해 사용자는 스스로 하루을 피드백을 할 수 있고 실수 혹은 본인이 인지하지 못했던 주제 등을 파악할 수 있다.
위와 마찬가지로 관심사, 습관 등을 파악할 수도 있다. 주간, 월간 통계를 통해서 과거를 쉽게 정리해서 본다는 것은 그를 통해서 앞으로의 일을 예측할 수도 있게 된다. 이에 따라 사용자는 본인의 진로에 대한 흥미로운 자료들을 쉽게 찾을 수 있게 된다.
작품 설명
주요동작 및 특징
본 아이템은 사용자가 했던 말을 팔찌를 통해 기능은 녹음과 블루투스 송수신을 하고, 스마트폰에 전송시켜 사용자에게 특정 단어를 얼마나 말했는지, 특정 시간에 있었던 내용은 주로 어떠한 내용이었는지를 알게 해주는 시스템이다.
이는 크게 일간, 주간 통계로 나뉘며 일간 통계의 경우 워드 클라우드와 선 그래프로 보이며 워드 클라우드는 가장 많이 말했던 단어와 크기를 비례해 한 눈에 볼 수 있다. 선 그래프의 경우 시간 단위로 끊어 언제 어떠한 단어를 몇 번 사용하였는지 사용자에게 알려주게 된다. 또한 특정 단어와 같이 말했던 단어들도 볼 수 있다.
주간 통계의 경우 꺾은선 그래프로만 이루어져 있으며 하루 단위로 나누어 사용자에게 어떠한 단어를 얼마나 사용하였는지 알려주게 된다. 이를 이용하여 사용자는 자신의 성향에 대해 알 수 있으며, 당일 있었던 내용을 상기시켜 다시 이해할 수 있고 자신의 악습관을 스스로 피드백 할 수 있는 기회가 생긴다.
팔찌와 연동되는 스마트폰 어플리케이션은 팔찌와 블루투스 연결이 되어있는 동안 수신받는 단어들을 저장하며, 시간, 일간으로 나누어 같은 단어의 개수가 추가될 때마다 카운터를 한 개씩 올리며 통계를 낸 뒤 워드 클라우드와 그래프로 사용자에게 보여주게 된다.
또한 사용자가 특정 단어를 왜 사용하였는지 모르는 경우에 특정 단어를 기준으로 5초 동안의 정보를 단어에 저장하여, 소비자는 왜 그 단어를 사용하였는지 기억할 수 있고 해당 내용에 대해 이해하기가 매우 수월해질 수 있다.
그래프 화면에서 특정 단어를 클릭하게 되면 특정 단어를 당일 얼마나 사용했는지, 주간동안 얼마나 사용하였는지, 월간동안 얼마나 사용하였는지 숫자를 이용한 수치로 사용자에게 보이게 된다. 또한 특정 단어의 화면에서 같이 사용됐던 단어들을 나오게 하여 왜 그러한 단어를 사용하였는지 사용자가 알아차릴 수 있게 도와준다.
하드웨어 개요
본 아이템의 팔찌는 기존의 스마트 워치와 비슷한 소재를 사용하여 주 소재는 스테인리스를 사용해 제작할 예정이다. 이를 통해 최대한 사용자에게 거부감 없는, 가벼운 소재의 제품을 제공할 계획이다.
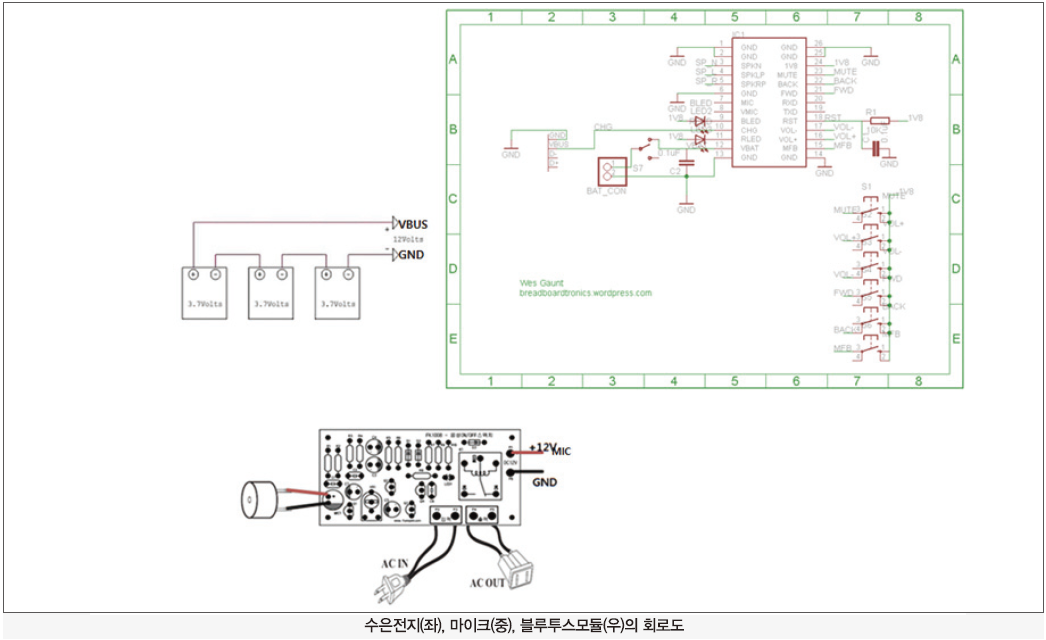
팔찌에는 스마트폰과 통신할 수 있는 5V 블루투스 모듈과, 사용자의 목소리를 수신할 수 있는 마이크가 삽입되어 있다. 팔찌는 수은전지로 전원을 넣게 되며, 블루투스의 전원 버튼을 누르고 스마트폰의 블루투스 모드를 ON하게 되면 팔찌 내의 블루투스와 스마트폰이 페어링을 하게 됨으로써 스마트폰과 블루투스가 통신을 할 수 있게 된다.
소프트웨어 개요

본 아이템은 음성데이터를 분석통계하는 어플리케이션이다. 팔찌로부터 음성을 읽어들여 단어를 저장하고 사용자가 사용했던 단어들을 확인하며 스스로 관리할 수 있도록 한다. 팔찌로부터 단어가 수신될 때마다 모든 단어들을 저장하며 그래프로 통계를 내어 사용자에게 보여주고 단어를 사용한 횟수 또한 사용자에게 보여지게 된다.
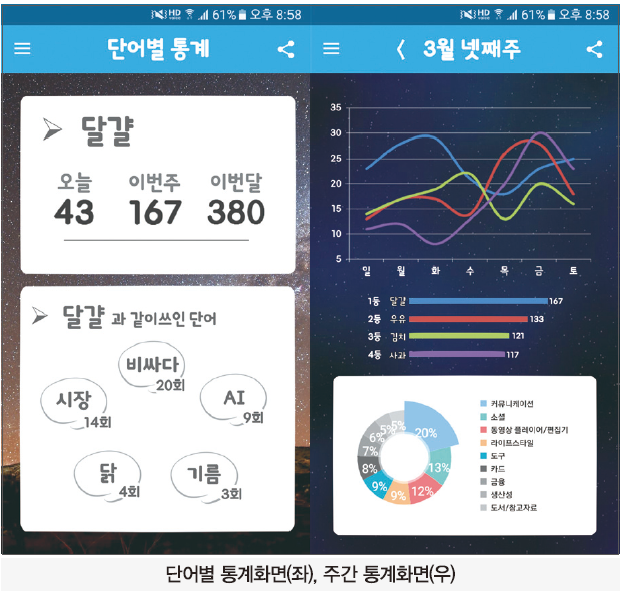
본 어플리케이션의 첫 화면인 일간통계 화면에서의 워드 클라우드는 정해놓은 여러 가지의 색을 기준으로 특정 단어의 카운터 수와 크기가 비례하도록 프로그래밍 하여 사용자에게 핵심단어를 시각화 하고 대화의 키워드, 개념을 직관적으로 파악할 수 있도록 한다.
워드 클라우드는 사용자가 특정한 단어를 말할 때 마다 항상 어플리케이션에 업데이트가 되며 각각의 단어의 크기와 색이 변하게 된다. 그래프의 경우 특정 단어에 대해 시간과 횟수를 기준으로 사용자에게 보여지게 된다.
통계는 일간, 주간, 월간을 기준으로 나눠놓았으며 각각 24시간, 한 주, 한 달을 지정해놓아 저장되어 있는 데이터를 불러오는 방식이다.
일간통계 화면에서 좌측으로 드래그를 하게 되면 주간통계 화면으로 넘어가게 된다. 주간통계 화면 부분에는 워드 클라우드가 없으며 그래프로 한 주간 사용했던 데이터들을 모아 사용자가 한눈에 볼 수 있도록 해준다.
일간, 주간통계 그래프에서 특정 단어를 클릭할 때 특정 단어에 대한 정보가 나오게 된다. 해당 화면 하단에는 특정 단어와 5초 간격으로 사용된 단어들을 표시해 준다. 이 단어들로 하여금 사용자는 자신이 사용했던 단어들을 쉽게 이해할 수 있으며 특정 시간에 왜 이러한 단어를 사용하였는지 기억을 되새길 수 있다.
하지만 아직까지 음성데이터의 인식률 문제가 있어, 한국어 음성인식 같은 경우는 비슷할 뿐 존재하지 않는 단어를 출력하여 사용자에게 보여주게 된다.
본 아이템의 어플리케이션은 음성인식의 신뢰성을 높이기 위해 어플리케이션 내에 한글단어 데이터베이스를 추가하고, 이를 이용한 ‘오인식 글자 수정 시스템’을 도입할 예정이다.
음성인식에 대한 신뢰성이 높지 않은 시스템들과 비교하자면, 본 아이템은 틀린 단어와 철자를 비교해 비슷한 철자의 단어를 사용자에게 보여주어 일치하는지 아닌지 판단하게끔 한다.
예를 들어, ‘마우스’라는 단어가 수신하고자 할 경우 컴퓨터는 ‘미우스’, ‘마오스’ 등 잘못된 수신을 할 수 있다. 하지만 한글단어 데이터베이스를 사용하여 특정 단어와 잘못 수신된 단어의 철자가 비슷한지의 여부를 확인하고 비슷할 경우 사용자에게 ‘미우스’라는 단어가 ‘마우스’가 맞는지에 대한 판단를 물어보게 된다. 사용자에게 주어진 선택지를 이용하여 해당 단어가 맞다고 판단할 경우 ‘미우스’라고 수신되는 단어는 항상 ‘마우스’ 주소로 가게 된다.
하지만 ‘미우스’라는 단어가 ‘마우스’가 아니라고 사용자가 판단할 경우 ‘미우스’라는 단어는 더 이상 ‘마우스’가 아닌 것을 데이터베이스에 저장하여 음성인식의 신뢰도를 더욱 높일 수 있다.
이러한 오인식 글자 수정 시스템은 특정 단어화면에서 뿐만 아니라 상태 바에 알림으로도 나오며 바탕화면 위젯을 이용하여 사용자에게 인식 판단 여부를 물어볼 수 있다. 사용자에게 많은 참여를 이끌고 이를 데이터화한다면 음성 인식률을 더욱 향상시킬 수 있을 것으로 예상된다.
한글 단어 데이터베이스를 활용하여 단어를 분류한 뒤 사용자에게 분류한 통계자료를 보여줄 수 있다.
예를 들어 ‘설거지’라는 단어가 수신되어 어플리케이션에 등록이 될 경우 ‘설거지’ 라는 단어의 분류는 사전에서 ‘가정, 생활’분류에 포함되기 때문에 사용자는 어떠한 분류에 관심이 많은지, 어떠한 분류에 관심이 없는지 스스로가 보며 자기 자신을 피드백 할 수 있다.
본 아이템의 어플리케이션에서 제공되는 단어 사용 횟수, 어플리케이션에서 제공하는 단어의 정보에 대한 분류 후 특정 단어에 대한 정보, 특정 시간에서의 단어 사용을 사용자가 알고 이를 통하여 사용자는 자기 자신에 대해 알아가며 자신의 성향은 어떠한지 자신의 진로는 어떠한지에 대해 스스로를 피드백 할 수 있다.
개발 환경(개발 언어, Tool, 사용 시스템 등)
어플리케이션 개발에 있어서 오픈소스와 안드로이드 SDK, 앱 인벤터를 주요 툴로 사용하였고, 개발 환경으로는 리눅스 환경, Python, Java 등을 주로 이용하였다.
단계별 제작과정
하드웨어 제작과정
본 아이디어에 대해 실현가능성을 검토하기 위해서 본 팀은 아두이노와 아두이노 블루투스 모듈, 간이 녹음기를 통해 실험을 했으며 결과, 그 데이터가 스마트폰으로 정상 수신되는 것을 확인할 수 있었다.
그 후 1차 시제품을 만드는 데에 성공했다. 1차 시제품의 구성은 고무밴드에 아두이노 기반 블루투스 마이크 모듈을 설치하고 모듈에 전원을 넣을 수 있는 5V 수은전지 공간을 추가하여 제작했으며, 이 시제품으로 기능 작동 실험에 성공했다.
1차 시제품 이후에는 가벼운 스테인리스 소재나 플라스틱 등 기존 스마트워치 디자인 중 하나를 택해 팔찌를 제작할 예정이다. 2차 시제품은 사용자는 휴대하기 편리하고 신체에 무리가 가지 않으며 사용하기도 간편한 재료로 제작을 진행할 예정이다.
소프트웨어 제작과정
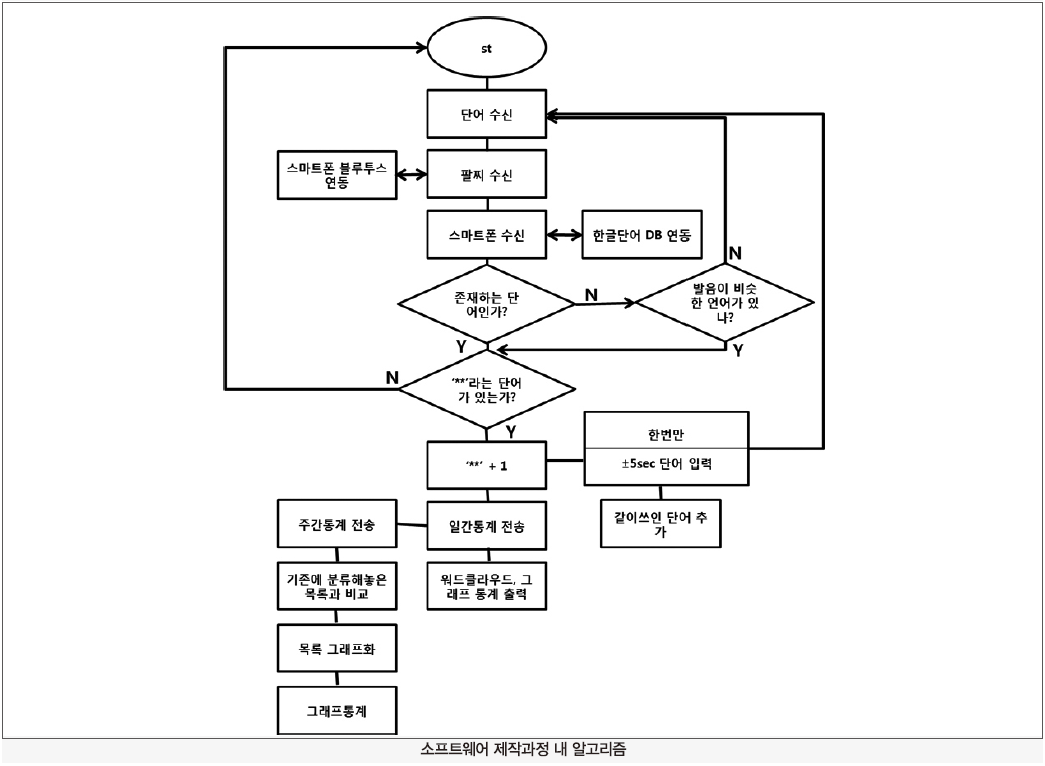
본 아이템은 안드로이드 SDK 오픈소스를 기반하여 제작하였다. 팔찌는 블루투스를 이용하여 스마트폰과 통신을 한다.
어플리케이션에는 한글단어 데이터베이스를 입력하여 수신된 단어와 비교한다. 예를 들어, 팔찌에 ‘친구야’라는 단어가 수신될 경우 스마트폰과 블루투스로 통신하여 어플리케이션은 ‘친구야’라는 단어를 수신 받는다. 어플리케이션은 내장되어있는 한글단어 데이터베이스와 비교하여 어플리케이션에게 존재하는 단어인지 검증한다. 위 검증 과정에서 수신받은 단어가 존재하는 단어가 아니라고 판단될 경우 수신받은 단어와 자음이나 모음이 비슷한 단어가 있는지 검증하게 된다. 아니라고 할 경우 단어를 수신받기 전으로 돌아가 단어를 수신 받을 때까지 대기상태가 된다. 대기상태에서 단어를 수신 받을 경우 이 과정을 다시 거치게 된다.
수신받은 단어와 검증한 단어가 일치할 경우 시스템 상에서 해당 단어를 카운트해 저장할 수 있도록 하고, 이를 통계에 포함시킨다.
위 과정을 거치며 처음에는 신뢰성이 떨어질 수 있으나 점차 많은 단어가 수신될수록 신뢰도는 급격히 높아질 것이다.
‘친구’라는 단어를 카운트한 경우 ‘친구’라는 단어가 수신된 시작에서 5초 범위로 같이 수신된 단어들을 입력하여 같이 쓰인 단어 목록에 추가된다. 이후 카운트된 ‘친구’라는 단어는 일간 통계에 전송된 후 주간 통계로 보내지게 된다.
주간 통계는 그래프 통계로, 매주 업데이트 되며 위 어플리케이션에서 소셜, 생활, 문학, 음식, 지식 등 분류해 놓은 목록들과 ‘친구’라는 단어를 비교한 뒤 퍼센트 단위로 구분하여 그래프로 사용자에게 한눈에 보여준다. 일간 통계는 단어 클라우드와 그래프 통계가 수시로 업데이트 되어 사용자에게 보여지게 된다. 단어 클라우드는 사용한 단어의 횟수와 단어 크기를 비례하여 보여준다. 단어 사용 빈도를 기준으로 가운데서부터 끝으로 갈수록 점차 단어의 크기가 작아지게 된다. 그래프 통계는 사용 빈도가 높은 단어를 기준하여 내림차순으로 사용자에게 보여지게 된다.
어플리케이션 워드클라우드 생성 소스코드(리눅스, 파이썬)
from __future__ import division
import warnings
from random import Random
import os
import re
import sys
import colorsys
import numpy as np
from operator import itemgetter
from PIL import Image
from PIL import ImageColor
from PIL import ImageDraw
from PIL import ImageFont
from .query_integral_image import query_integral_image
from .tokenization import unigrams_and_bigrams, process_tokens
item1 = itemgetter(1)
FONT_PATH = os.environ.get(“FONT_PATH”, os.path.join(os.path.dirname(__file__),
“DroidSansMono.ttf”))
STOPWORDS = set([x.strip() for x in open(
os.path.join(os.path.dirname(__file__), 'stopwords')).read().split('\n')])
class IntegralOccupancyMap(object):
def __init__(self, height, width, mask):
self.height = height
self.width = width
if mask is not None:
# the order of the cumsum’s is important for speed ?!
self.integral = np.cumsum(np.cumsum(255 * mask, axis=1),
axis=0).astype(np.uint32)
else:
self.integral = np.zeros((height, width), dtype=np.uint32)
def sample_position(self, size_x, size_y, random_state):
return query_integral_image(self.integral, size_x, size_y,
random_state)
def update(self, img_array, pos_x, pos_y):
partial_integral = np.cumsum(np.cumsum(img_array[pos_x:, pos_y:],
axis=1), axis=0)
# paste recomputed part into old image
# if x or y is zero it is a bit annoying
if pos_x > 0:
if pos_y > 0:
partial_integral += (self.integral[pos_x - 1, pos_y:]
- self.integral[pos_x - 1, pos_y - 1])
else:
partial_integral += self.integral[pos_x - 1, pos_y:]
if pos_y > 0:
partial_integral += self.integral[pos_x:, pos_y - 1][:, np.newaxis]
self.integral[pos_x:, pos_y:] = partial_integral
def random_color_func(word=None, font_size=None, position=None,
orientation=None, font_path=None, random_state=None):
“”"Random hue color generation.
Default coloring method. This just picks a random hue with value 80% and
lumination 50%.
Parameters
———————————————–
word, font_size, position, orientation : ignored.
random_state : random.Random object or None, (default=None)
If a random object is given, this is used for generating random
numbers.
“”"
if random_state is None:
random_state = Random()
return “hsl(%d, 80%%, 50%%)” % random_state.randint(0, 255)
class colormap_color_func(object):
“”"Color func created from matplotlib colormap.
Parameters
———————————————–
colormap : string or matplotlib colormap
Colormap to sample from
Example
———————————————–
>>> WordCloud(color_func=colormap_color_func(“magma”))
“”"
def __init__(self, colormap):
import matplotlib.pyplot as plt
self.colormap = plt.cm.get_cmap(colormap)
def __call__(self, word, font_size, position, orientation,
random_state=None, **kwargs):
if random_state is None:
random_state = Random()
r, g, b, _ = 255 * np.array(self.colormap(random_state.uniform(0, 1)))
return “rgb({:.0f}, {:.0f}, {:.0f})”.format(r, g, b)
def get_single_color_func(color):
“”"Create a color function which returns a single hue and saturation with.
different values (HSV). Accepted values are color strings as usable by
PIL/Pillow.
>>> color_func1 = get_single_color_func(‘deepskyblue’)
>>> color_func2 = get_single_color_func(‘#00b4d2′)
“”"
old_r, old_g, old_b = ImageColor.getrgb(color)
rgb_max = 255.
h, s, v = colorsys.rgb_to_hsv(old_r / rgb_max, old_g / rgb_max,
old_b / rgb_max)
def single_color_func(word=None, font_size=None, position=None,
orientation=None, font_path=None, random_state=None):
“”"Random color generation.
Additional coloring method. It picks a random value with hue and
saturation based on the color given to the generating function.
Parameters
———————————————–
word, font_size, position, orientation : ignored.
random_state : random.Random object or None, (default=None)
If a random object is given, this is used for generating random
numbers.
“”"
if random_state is None:
random_state = Random()
r, g, b = colorsys.hsv_to_rgb(h, s, random_state.uniform(0.2, 1))
return ‘rgb({:.0f}, {:.0f}, {:.0f})’.format(r * rgb_max, g * rgb_max,
b * rgb_max)
return single_color_func
class WordCloud(object):
“”"Word cloud object for generating and drawing.
Parameters
———————————————–
font_path : string
Font path to the font that will be used (OTF or TTF).
Defaults to DroidSansMono path on a Linux machine. If you are on
another OS or don’t have this font, you need to adjust this path.
width : int (default=400)
Width of the canvas.
height : int (default=200)
Height of the canvas.
prefer_horizontal : float (default=0.90)
The ratio of times to try horizontal fitting as opposed to vertical.
If prefer_horizontal < 1, the algorithm will try rotating the word
if it doesn’t fit. (There is currently no built-in way to get only vertical words.)
mask : nd-array or None (default=None)
If not None, gives a binary mask on where to draw words. If mask is not
None, width and height will be ignored and the shape of mask will be
used instead. All white (#FF or #FFFFFF) entries will be considerd
“masked out” while other entries will be free to draw on. [This
changed in the most recent version!]
scale : float (default=1)
Scaling between computation and drawing. For large word-cloud images,
using scale instead of larger canvas size is significantly faster, but
might lead to a coarser fit for the words.
min_font_size : int (default=4)
Smallest font size to use. Will stop when there is no more room in this size.
font_step : int (default=1)
Step size for the font. font_step > 1 might speed up computation but
give a worse fit.
max_words : number (default=200)
The maximum number of words.
stopwords : set of strings or None
The words that will be eliminated. If None, the build-in STOPWORDS
list will be used.
background_color : color value (default=”black”)
Background color for the word cloud image.
max_font_size : int or None (default=None)
Maximum font size for the largest word. If None, height of the image is
used.
mode : string (default=”RGB”)
Transparent background will be generated when mode is “RGBA” and
background_color is None.
relative_scaling : float (default=.5)
Importance of relative word frequencies for font-size. With
relative_scaling=0, only word-ranks are considered. With
relative_scaling=1, a word that is twice as frequent will have twice
the size. If you want to consider the word frequencies and not only
their rank, relative_scaling around .5 often looks good.
.. versionchanged: 2.0
Default is now 0.5.
color_func : callable, default=None
Callable with parameters word, font_size, position, orientation,
font_path, random_state that returns a PIL color for each word.
Overwrites “colormap”.
See colormap for specifying a matplotlib colormap instead.
regexp : string or None (optional)
Regular expression to split the input text into tokens in process_text.
If None is specified, “r”\w[\w']+”“ is used.
collocations : bool, default=True
Whether to include collocations (bigrams) of two words.
.. versionadded: 2.0
colormap : string or matplotlib colormap, default=”viridis”
Matplotlib colormap to randomly draw colors from for each word.
Ignored if “color_func” is specified.
.. versionadded: 2.0
normalize_plurals : bool, default=True
Whether to remove trailing ‘s’ from words. If True and a word
appears with and without a trailing ‘s’, the one with trailing ‘s’
is removed and its counts are added to the version without
trailing ‘s’ — unless the word ends with ‘ss’.
Attributes
———————————————–
“words_“ : dict of string to float
Word tokens with associated frequency.
.. versionchanged: 2.0
“words_“ is now a dictionary
“layout_“ : list of tuples (string, int, (int, int), int, color))
Encodes the fitted word cloud. Encodes for each word the string, font
size, position, orientation and color, Notes
———————————————–
Larger canvases with make the code significantly slower. If you need a
large word cloud, try a lower canvas size, and set the scale parameter.
The algorithm might give more weight to the ranking of the words
than their actual frequencies, depending on the “max_font_size“ and the
scaling heuristic.
“”"
def __init__(self, font_path=None, width=400, height=200, margin=2,
ranks_only=None, prefer_horizontal=.9, mask=None, scale=1,
color_func=None, max_words=200, min_font_size=4,
stopwords=None, random_state=None, background_color=’black’,
max_font_size=None, font_step=1, mode=”RGB”,
relative_scaling=.5, regexp=None, collocations=True,
colormap=None, normalize_plurals=True):
if font_path is None:
font_path = FONT_PATH
if color_func is None and colormap is None:
# we need a color map
import matplotlib
version = matplotlib.__version__
if version[0] < “2″ and version[2] < “5″:
colormap = “hsv”
else:
colormap = “viridis”
self.colormap = colormap
self.collocations = collocations
self.font_path = font_path
self.width = width
self.height = height
self.margin = margin
self.prefer_horizontal = prefer_horizontal
self.mask = mask
self.scale = scale
self.color_func = color_func or colormap_color_func(colormap)
self.max_words = max_words
self.stopwords = stopwords if stopwords is not None else STOPWORDS
self.min_font_size = min_font_size
self.font_step = font_step
self.regexp = regexp
if isinstance(random_state, int):
random_state = Random(random_state)
self.random_state = random_state
self.background_color = background_color
self.max_font_size = max_font_size
self.mode = mode
if relative_scaling < 0 or relative_scaling > 1:
raise ValueError(“relative_scaling needs to be ”
“between 0 and 1, got %f.” % relative_scaling)
self.relative_scaling = relative_scaling
if ranks_only is not None:
warnings.warn(“ranks_only is deprecated and will be removed as”
” it had no effect. Look into relative_scaling.”,
DeprecationWarning)
self.normalize_plurals = normalize_plurals
def fit_words(self, frequencies):
“”"Create a word_cloud from words and frequencies.
Alias to generate_from_frequencies.
Parameters
———————————————–
frequencies : array of tuples
A tuple contains the word and its frequency.
Returns
———————————————–
self
“”"
return self.generate_from_frequencies(frequencies)
def generate_from_frequencies(self, frequencies, max_font_size=None):
“”"Create a word_cloud from words and frequencies.
Parameters
———————————————–
frequencies : dict from string to float
A contains words and associated frequency.
max_font_size : int
Use this font-size instead of self.max_font_size
Returns
———————————————–
self
“”"
# make sure frequencies are sorted and normalized
frequencies = sorted(frequencies.items(), key=item1, reverse=True)
if len(frequencies) <= 0:
raise ValueError(“We need at least 1 word to plot a word cloud, ”
“got %d.” % len(frequencies))
frequencies = frequencies[:self.max_words]
# largest entry will be 1
max_frequency = float(frequencies[0][1])
frequencies = [(word, freq / max_frequency)
for word, freq in frequencies]
if self.random_state is not None:
random_state = self.random_state
else:
random_state = Random()
if self.mask is not None:
mask = self.mask
width = mask.shape[1]
height = mask.shape[0]
if mask.dtype.kind == ‘f’:
warnings.warn(“mask image should be unsigned byte between 0″
” and 255. Got a float array”)
if mask.ndim == 2:
boolean_mask = mask == 255
elif mask.ndim == 3:
# if all channels are white, mask out
boolean_mask = np.all(mask[:, :, :3] == 255, axis=-1)
else:
raise ValueError(“Got mask of invalid shape: %s”
% str(mask.shape))
else:
boolean_mask = None
height, width = self.height, self.width
occupancy = IntegralOccupancyMap(height, width, boolean_mask)
# create image
img_grey = Image.new(“L”, (width, height))
draw = ImageDraw.Draw(img_grey)
img_array = np.asarray(img_grey)
font_sizes, positions, orientations, colors = [], [], [], []
last_freq = 1.
if max_font_size is None:
# if not provided use default font_size
max_font_size = self.max_font_size
if max_font_size is None:
# figure out a good font size by trying to draw with
# just the first two words
if len(frequencies) == 1:
# we only have one word. We make it big!
font_size = self.height
else:
self.generate_from_frequencies(dict(frequencies[:2]),
max_font_size=self.height)
# find font sizes
sizes = [x[1] for x in self.layout_]
font_size = int(2 * sizes[0] * sizes[1] / (sizes[0] + sizes[1]))
else:
font_size = max_font_size
# we set self.words_ here because we called generate_from_frequencies
# above… hurray for good design?
self.words_ = dict(frequencies)
# start drawing grey image
for word, freq in frequencies:
# select the font size
rs = self.relative_scaling
if rs != 0:
font_size = int(round((rs * (freq / float(last_freq))
+ (1 – rs)) * font_size))
if random_state.random() < self.prefer_horizontal:
orientation = None
else:
orientation = Image.ROTATE_90
tried_other_orientation = False
while True:
# try to find a position
font = ImageFont.truetype(self.font_path, font_size)
# transpose font optionally
transposed_font = ImageFont.TransposedFont(
font, orientation=orientation)
# get size of resulting text
box_size = draw.textsize(word, font=transposed_font)
# find possible places using integral image:
result = occupancy.sample_position(box_size[1] + self.margin,
box_size[0] + self.margin,
# if we didn’t find a place, make font smaller
# but first try to rotate!
if not tried_other_orientation and self.prefer_horizontal < 1:
orientation = (Image.ROTATE_90 if orientation is None else
Image.ROTATE_90)
tried_other_orientation = True
else:
font_size -= self.font_step
orientation = None
if font_size < self.min_font_size:
# we were unable to draw any more
break
x, y = np.array(result) + self.margin // 2
# actually draw the text
draw.text((y, x), word, fill=”white”, font=transposed_font)
positions.append((x, y))
orientations.append(orientation)
font_sizes.append(font_size)
colors.append(self.color_func(word, font_size=font_size,
position=(x, y),
, _ = process_tokens(words, self.normalize_plurals)
return word_counts
def generate_from_text(self, text):
“”"Generate wordcloud from text.
Calls process_text and generate_from_frequencies.
..versionchanged:: 1.2.2
Argument of generate_from_frequencies() is not return of
process_text() any more.
Returns
———————————————–
self
“”"
words = self.process_text(text)
self.generate_from_frequencies(words)
return self
def generate(self, text):
“”"Generate wordcloud from text.
Alias to generate_from_text.
Calls process_text and generate_from_frequencies.
Returns
———————————————–
self
“”"
return self.generate_from_text(text)
def _check_generated(self):
“”"Check if “layout_“ was computed, otherwise raise error.”"”
if not hasattr(self, “layout_”):
raise ValueError(“WordCloud has not been calculated, call generate”
” first.”)
def to_image(self):
self._check_generated()
if self.mask is not None:
width = self.mask.shape[1]
height = self.mask.shape[0]
else:
height, width = self.height, self.width
img = Image.new(self.mode, (int(width * self.scale),
int(height * self.scale)),
self.background_color)
draw = ImageDraw.Draw(img)
for (word, count), font_size, position, orientation, color in self.layout_:
font = ImageFont.truetype(self.font_path,
int(font_size * self.scale))
transposed_font = ImageFont.TransposedFont(
font, orientation=orientation)
pos = (int(position[1] * self.scale),
int(position[0] * self.scale))
draw.text(pos, word, fill=color, font=transposed_font)
return img
def recolor(self, random_state=None, color_func=None, colormap=None):
“”"Recolor existing layout.
Applying a new coloring is much faster than generating the whole
wordcloud.
Parameters
———————————————–
random_state : RandomState, int, or None, default=None
If not None, a fixed random state is used. If an int is given, this
is used as seed for a random.Random state.
color_func : function or None, default=None
Function to generate new color from word count, font size, position
and orientation. If None, self.color_func is used.
colormap : string or matplotlib colormap, default=None
Use this colormap to generate new colors. Ignored if color_func
is specified. If None, self.color_func (or self.color_map) is used.
Returns
———————————————–
self
“”"
if isinstance(random_state, int):
random_state = Random(random_state)
self._check_generated()
if color_func is None:
if colormap is None:
color_func = self.color_func
else:
color_func = colormap_color_func(colormap)
self.layout_ = [(word_freq, font_size, position, orientation,
color_func(word=word_freq[0], font_size=font_size,
position=position, orientation=orientation,
random_state=random_state,
font_path=self.font_path))
for word_freq, font_size, position, orientation, _
in self.layout_]
return self
def to_file(self, filename):
“”"Export to image file.
Parameters
———————————————–
filename : string
Location to write to.
Returns
———————————————–
self
“”"
img = self.to_image()
img.save(filename)
return self
def to_array(self):
“”"Convert to numpy array.
Returns
———————————————–
image : nd-array size (width, height, 3)
Word cloud image as numpy matrix.
“”"
return np.array(self.to_image())
def __array__(self):
“”"Convert to numpy array.
Returns
———————————————–
image : nd-array size (width, height, 3)
Word cloud image as numpy matrix.
“”"
return self.to_array()
def to_html(self):
raise NotImplementedError(“FIXME!!!”)
기타(회로도, 소스코드, 참고문헌 등)